
A few weeks ago I wrote about starting an new application to scrape for references to a domain. The following week I wrote about streaming data from and Elixir server processes and described how I could apply that technique to decouple the processing of streams in my new application.
At the moment, I’m calling this application Domain Scraper and, thus far, it exists only as a series of improving prototypes used to flesh out the design. This week, I’ll update the design of domain scrapper to use a process pool to manage the work in my application.
Pools
Pools are a very common component of Erlang and Elixir applications. A pool manages a set of processes that can perform work. The pool eliminates the need to start and stop processes on demand and instead allows clients to reuse the existing processes in the pool.
If you’re looking for more information, the chapter on pools in Learn you some Erlang for Great Good! gives a great description of pools and even describes how to implement one.
We can try using a pool of processes to handle URL unshortening in Domain Scraper. Previously, I used a queue of asynchronous tasks for this purpose. Using a pool differs from using a queue in that the queue can get blocked if one URL takes a very long time to unshorten. In the queued based scheme all urls submitted to the queue afterwards will be blocked. This was something that was pointed out to me when I presented the the previous prototype iteration to the Elixir / Erlang Silicon Valley meetup. With a pool there is no ordering of work so if one process take a long time, other pool workers can still complete their tasks and pick up new URLs to process.
Prototyping a solution
I started off my pool experiment using a standalone prototype. It’s simply called P7 as it’s the 7th prototype I’ve built for the project. The first 6 prototypes were iterations on the same program. The source to p7 is on github.
Setting up Poolboy
Poolboy is an Erlang pool manager which I’ve decided to use in this prototype. To get it setup I needed to create a supervised application like this:
$ mix new --sup p7With the --sup flag the P7 module gets a start function that starts up the supervision tree for the application. Within this function we can add the poolboy application to the supervision tree.
def start(_type, _args) do
import Supervisor.Spec, warn: false
children = [
:poolboy.child_spec(pool_name(), poolboy_config(), [])
]
# See http://elixir-lang.org/docs/stable/elixir/Supervisor.html
# for other strategies and supported options
opts = [strategy: :one_for_one, name: P7.Supervisor]
Supervisor.start_link(children, opts)
end
def pool_name, do: :p7_pool
defp poolboy_config do
[
{:name, {:local, pool_name}},
{:worker_module, P7.Worker},
{:size, 5},
{:max_overflow, 10}
]
endThe children specification holds most of the relevant details. For more information on setting up poolboy see the poolboy repo and its README.
The interface
After setting up poolboy I needed to decide on the interface for streaming work through the pool.
When I started this prototype I wanted to use Enum.into/2 as a model for my interface, thinking that the pool would implement the Collectable protocol. However, as I worked through development of the prototype I realized this doesn’t make sense. To collect into a pool would mean that the pool was a data sink. But, this is not the case. The pool does work and transforms a stream of data into a new stream like this:

That said, I wrote the prototype using an into interface that looks like this:
PoolUtil.into([1, 2, 3], [], via: pool_name)I did end up with the via: keyword option indicating that the pool is a conduit rather than the sink itself. Given this interface, I wrote this test:
test "it should collect via the the pool" do
assert [2, 3, 4] ==
[1, 2, 3]
|> PoolUtil.into([], via: P7.pool_name())
|> Enum.take(3)
|> Enum.sort
endImplementation
Here’s the implementation I wrote:
defmodule P7.PoolUtil do
def into(enum, col, opts) do
pool = opts[:via]
{:ok, queue} = BlockingQueue.start_link(:infinity)
enum
|> resource(pool, queue)
|> extract_and_checkin(pool)
|> Stream.into(col, fn x -> x end)
end
defp resource(enum, pool, queue) do
Stream.resource(
fn ->
spawn_link fn -> stream_through_pool(enum, pool, queue) end
end,
fn _ -> {[BlockingQueue.pop(queue)], nil} end,
fn _ -> true end
)
end
defp stream_through_pool(enum, pool, queue) do
enum
|> Enum.map(fn x -> {x, :poolboy.checkout(pool)} end)
|> Enum.map(fn {x, worker} -> P7.Worker.work(worker, queue, x) end)
end
defp extract_and_checkin(stream, pool) do
Stream.map stream, fn {worker, result} ->
:poolboy.checkin(pool, worker)
result
end
end
endThe function P7.PoolUtil.into/3 has the interface we picked out. It starts by starting a BlockingQueue of infinite size. This is a new feature in blocking_queue which only blocks when poping from an empty queue.
Next, we compose several operations to build up a stream: first, we call resource/3 to create the Stream that drives the work through the pool. This stream will send back a tuple that includes the result as well as the PID of the worker process from the pool. extract_and_checkin will extract this result and return the worker to the pool. Finally, we call Stream.into/3 to collect the results into its final location in col.
Let’s look at resource in detail: we find that P7.PoolUtil.resource/3 is just a wrapper over Stream.resource/3. It builds a Stream that calls stream_through_pool to start up and then generates a stream of results poped out of the BlockingQueue. In detail, stream_through_pool just maps the stream by checking out a worker from the pool and pushing the work into it. We already looked at building a Stream of results from BlockingQueue in Stream Patterns in Elixir 3. The only peice we are missing here is how the results are pushed into the stream in the first place. For that, we have to look at the module P7.Worker:
defmodule P7.Worker do
use ExActor.GenServer
defstart start_link(_), do: initial_state(0)
defcast work(queue, x) do
BlockingQueue.push(queue, {self, x + 1})
new_state(0)
end
endThis uses the excelent ExActor module to simplify the code for a GenServer. The work/2 function performs the task for us. This is just a simple worker that adds 1 to any number passed in. work/2 also requires a BlockingQueue – it uses the queue to pass back the results. We can see in the code that the result is computed and pushed into the queue. The results will eventually be popped out of the queue by the Stream.resource we built earlier. The reuslt is packaged up in a tuple containing along with the PID of the worker process and pushed into the queue.
Going back to P7.PoolUtil.extract_and_checkin/2, we can see that it just cleans things up and reorganizes the results. It takes apart the result tuple {worker, result} so it can give the worker back to poolboy. Then it simply returns the result into a new Stream.
Altogether the flow through this setup looks something like this:
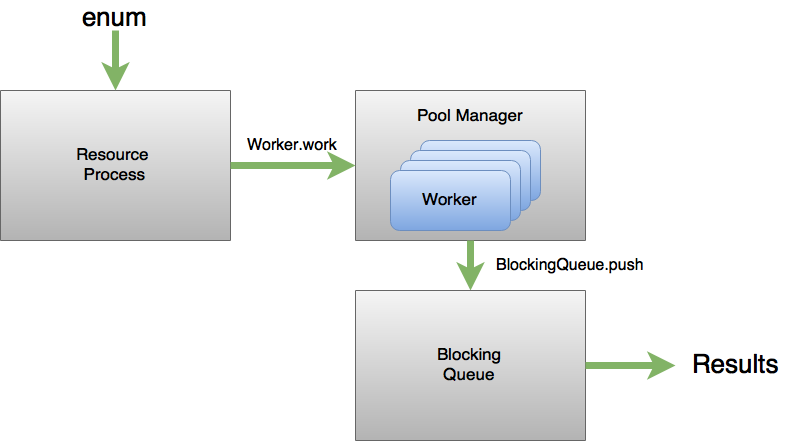
What did we learn from the prototype?
By building this prototype I learned a few things
-
I learned that I need a queue even with the pool. As we saw above I used the queue to collect the results.
-
Order is not preserved. The workers run asynchronously and can finish their jobs in any order. The results come out in this order. This is OK for the tasks I have in mind but won’t work for all cases. The test has to use
Enum.sortto generate consistent results at the end so that it can assert against a known value. -
The
into/3interface isn’t really buying me anything.intohas its uses but as we can see from the code we just tackintoonto the end of our composed operations. Our operation is really more like amapoperation, map through a pool.
Integrating into the app
The next step was to integrate the standalone prototype into the Twitter |> Parser |> Unshortener pipline I have in the prototype application.
This was pretty straight foward and mostly involved copying over the files and renaming some modules.
I also took the opportunity to change the interface from into to map_through_pool like this:
defmodule PoolUtil do
def map_through_pool(enum, pool) do
{:ok, queue} = BlockingQueue.start_link(:infinity)
enum
|> resource(pool, queue)
|> extract_and_checkin(pool)
end
# ...
endThe other big piece was to turn the P1 app into a supervised application and then start up poolboy. This was really just a matter of copying over the right code, including adding a start function to my P1 module.
I also uncovered a bug in stream_through_pool in that the function was too eager and didn’t work on the infinite ExTwitter stream. I fixed it by replacing calls to Enum.map with calls to Stream.map like this:
defp stream_through_pool(enum, pool, queue) do
enum
|> Stream.map(fn x -> {x, :poolboy.checkout(pool)} end)
|> Stream.map(fn {x, worker} -> Worker.work(worker, queue, x) end)
|> Stream.run
endNote that this is still eager evaluation but only in the last stage of the pipeline. The map calls need to be lazy so that the evaluation happens per element rather than per Enumerable.
After making all these changes I found that the performance seems somewhat faster. My measurements are unscientific as I don’t fetch the same tweets run-to-run but things seem faster, at least anecdotally. I may try to do some more careful measurements in the future. This does make sense as the pool should achieve better concurrency than the queue.
You can read over all the code for this version on github at the P8 tag.
Next Steps
In this post I was able to try out a pool based architecture for my application. At this point I think I’m pretty happy with these concurrency and design aspects of the app.
The next step is to wrap up the whole Twitter |> Parser |> Unshortener pipeline into an OTP application with supervision tree. I hope to write what I learn in doing this next week.